↳
In-reply-to
»
(#lnzctjq) (Now why is that GNOME
⤋ Read More
gcr thing running with debug logs enabled that print stuff like “sending secret exchange: …”? Is this healthy?)
@lyse@lyse.isobeef.org Looks like it. 🤔 Didn’t dig deeper into this, just uninstalled it. 🥴
(Now why is that GNOME gcr thing running with debug logs enabled that print stuff like “sending secret exchange: …”? Is this healthy?)
↳
In-reply-to
»
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
⤋ Read More
@lyse@lyse.isobeef.org Oh, huh, maybe it was just my GNOME 2 themes back then that didn’t show the icon. 🤔
I like the looks of your window manager. That’s using Wayland, right?
Oh, no. It’s still X11. All my recent Wayland comments resulted from me trying to switch, but I think it’s still too early. Being unable to use QEMU (because it can’t capture the mouse pointer) is a pretty big blocker for me. This is completely broken, it just happens to be unnoticeable with modern guest OSes, so it’s probably not a priority for devs.
(Not to mention that I would have to fork and substantially extend dwl in order to “replicate” my X11 WM. And then, after having done that, I’d have to follow upstream Wayland development, for which I don’t have the resources. Things would need to slow down before I can do that.)
all that wasted space of the windows not making use of the full screen!!!1
Heh. I’ve been using tiling WMs for ~15 years now, so it’s actually kind of refreshing to see something different for a change. 😅
Probably close to the older Windowses.
That particular theme is a ripoff of OS/2 Warp 3: 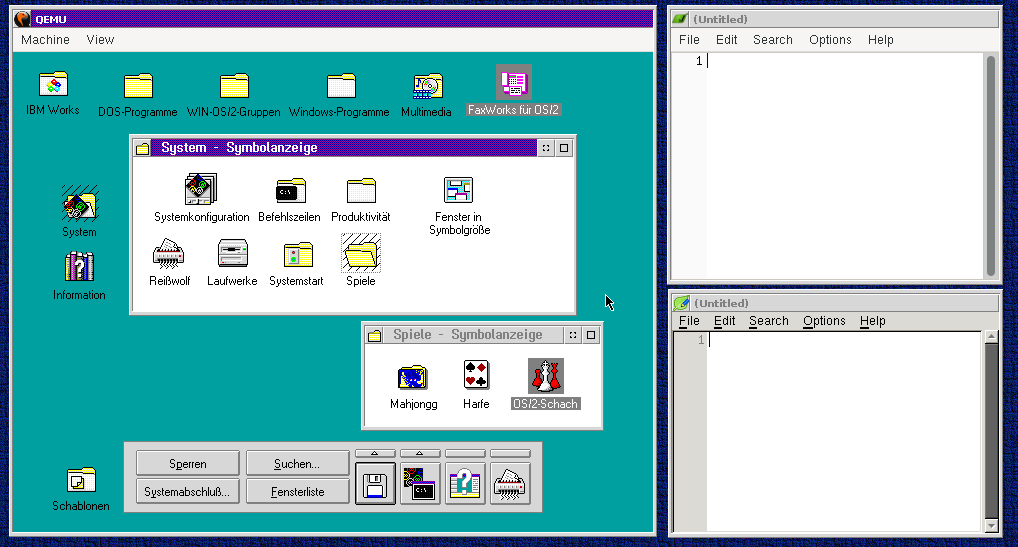 😅
😅
We ran some similar brownish color scheme (don’t recall its name) on Win95 or Win98
Oh god. Yeah, I wasn’t a fan of those, either. 🥴
↳
In-reply-to
»
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
⤋ Read More
@movq@www.uninformativ.de According to this screenshot, KDE still shows good old application icons:
And GNOME used to have them, too:
I like the looks of your window manager. That’s using Wayland, right? The only thing on this screenshot to critique is all that wasted space of the windows not making use of the full screen!!!1 At least the file browser. 8-)
This drives me nuts when my workmates share their screens. I really don’t get it how people can work like that. You can’t even read the whole line in the IDE or log viewer with all the expanded side bars. And then there’s 200 pixels on the left and another 300 pixels on the right where the desktop wallpaper shows. Gnaa! There’s the other extreme end when somebody shares their ultra wide screen and I just have a “regularish” 16:10 monitor and don’t see shit, because it’s resized way too tiny to fit my width. Good times. :-D
Sorry for going off on a tangent here. :-) Back to your WM: It has the right mix of being subtle and still similar to motif. Probably close to the older Windowses. My memory doesn’t serve me well, but I think they actually got it fairly good in my opinion. Your purple active window title looks killer. It just fits so well. This brown one (
) gives me also classic vibes. Awww. We ran some similar brownish color scheme (don’t recall its name) on Win95 or Win98 for some time on the family computer. I remember other people visting us not liking these colors. :-Dworking on a new astroJS based site and i hate being shit at web design because like i have the media for it ready (it’s for my fandom creations which are all done and ready to be shared here lol) but i keep agonizing over the design T__T
↳
In-reply-to
»
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
⤋ Read More
@lyse@lyse.isobeef.org True, at least old versions of KDE had icons:
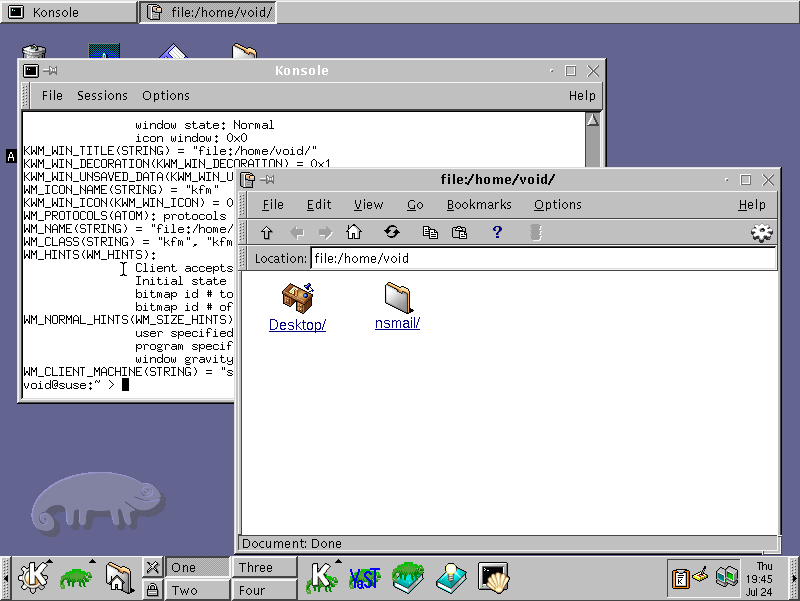
GNOME, on the other hand, didn’t, at least to my old screenshots from 2007:
I switched to Linux in 2007 and no window manager I used since then had icons, apparently. Crazy. An icon-less existence for 18 years. (But yeah, everything is keyboard-driven here as well and there are no buttons here, either.)
Anyway, my draft is making progress:
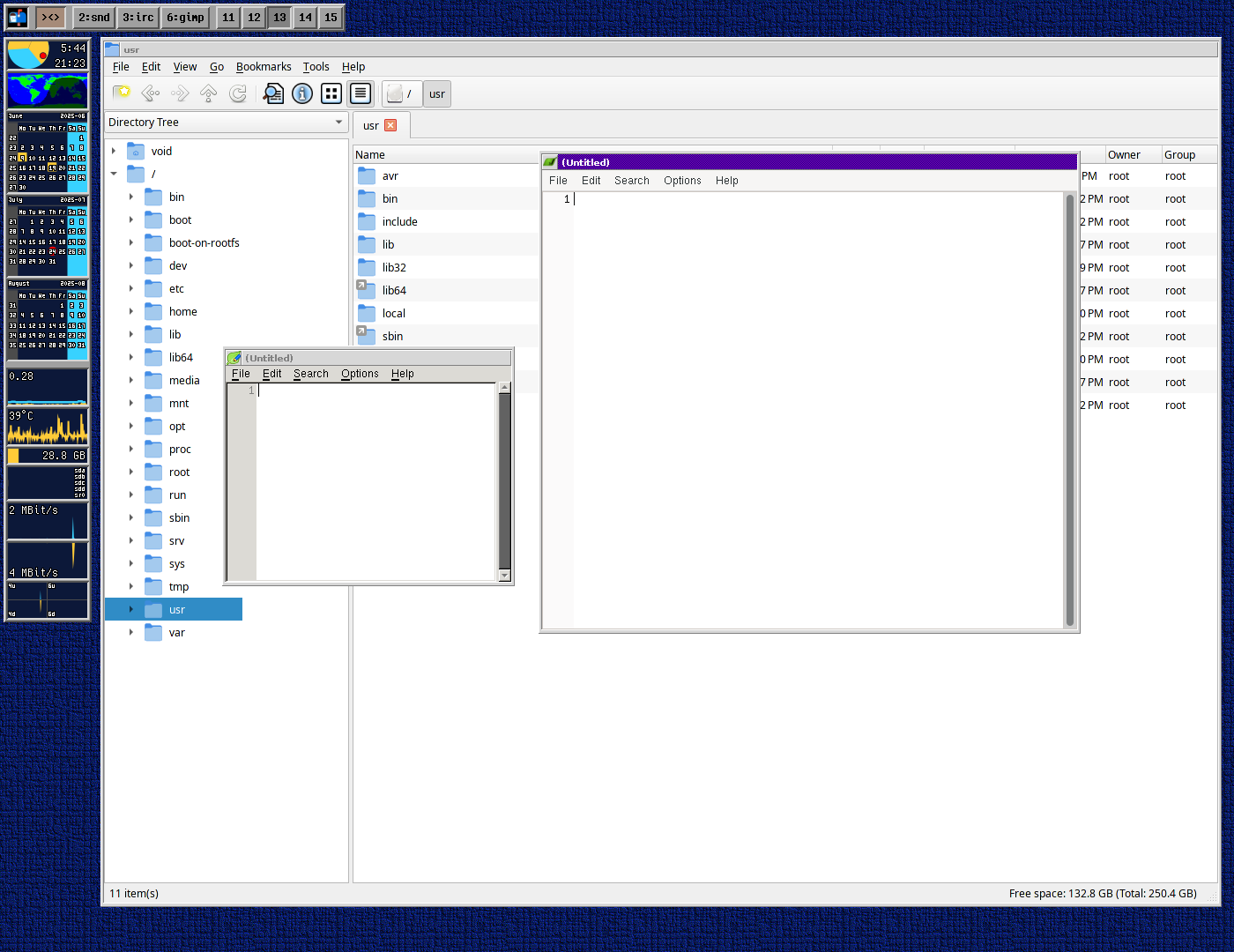
I do like this look. 😊
↳
In-reply-to
»
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
⤋ Read More
@movq@www.uninformativ.de I haven’t used KDE or GNOME for ages, but I’m sure KDE at least used to show application icons in the title bars. They proabably still do. But then, one could argue that KDE is mimicking Windows. I never thought like that, I always found KDE way superior, because I was able to configure it like a madman.
In i3, I don’t have any application icons. I remember missing them at the beginning. But I don’t even have the classical minimize, maximize and close buttons in the title bar either. Just the title. Being mostly keyboard driven and a tiling window manager, these buttons are not super useful, anyway.
Here’s an example of X11/Xlib being old and archaic.
X11 knows the data type “cardinal”. For example, the window property _NET_WM_ICON (which holds image data for icons) is an array of “cardinal”. I am already not really familiar with that word and I’m assuming that it comes from mathematics:
https://en.wikipedia.org/wiki/Cardinal_number
(It could also be a bird, but probably not: https://en.wikipedia.org/wiki/Cardinalidae)
We would probably call this an “integer” today.
EWMH says that icons are arrays of cardinals and that they’re 32-bit numbers:
https://specifications.freedesktop.org/wm-spec/latest-single/#id-1.6.13
So it’s something like 0x11223344 with 0x11 being the alpha channel, 0x22 is red, and so on.
You would assume that, when you retrieve such an array from the X11 server, you’d get an array of uint32_t, right?
Nope.
Xlib is so old, they use char for 8-bit stuff, short int for 16-bit, and long int for 32-bit:
That is congruent with the general C data types, so it does make sense:
https://en.wikipedia.org/wiki/C_data_types
Now the funny thing is, on modern x86_64, the type long int is actually 64 bits wide.
The result is that every pixel in a Pixmap, for example, is twice as large in memory as it would need to be. Just because Xlib uses long int, because uint32_t didn’t exist, yet.
And this is something that I wouldn’t know how to fix without breaking clients.
↳
In-reply-to
»
@lyse What’s bleeding edge? The mouse? Yeah, maybe. 😅 I didn’t buy that on purpose and didn’t even know hi-res mouse wheels were a thing …
⤋ Read More
@movq@www.uninformativ.de Following all your Wayland endeavors, it doesn’t sound like a mature and usable thing to me yet.
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
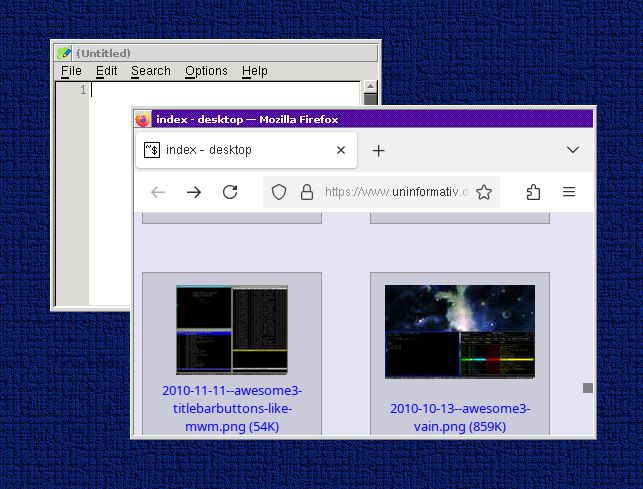
Then I realized: Wait a minute, lots of applications don’t set an icon? And lots of other window managers don’t show these icons, either? Openbox, pekwm, Xfce, fvwm, no icons.
Looks like macOS doesn’t show them, either?!
Has this grown out of fashion? Is this purely a Windows / OS/2 thing?
↳
In-reply-to
»
@lyse What’s bleeding edge? The mouse? Yeah, maybe. 😅 I didn’t buy that on purpose and didn’t even know hi-res mouse wheels were a thing …
⤋ Read More
@lyse@lyse.isobeef.org The cynic in me says: “It’s not bleeding edge, it’s from 2008!” That’s not fair, though, looks like the issue only arose in libinput in 2019. And maybe these weird mice are super rare. Dunno.
gomdn: Yet another Static Site Generator
Yet another Static Site Generator (SSG), but this one is mine.
It’s a stupidly simple Go program ( wc says 229 lines), more like a
hack, really, but I don’t need something like Hugo. Most of the real
work is done by the goldmark package, of course. This is mostly just a
wrapper, deciding if something needs to be rebuilt.
I’ve been using a Perl script together with cmark (originally
Markdown.pl) since forever. And before that the old [txt2tags](htt … ⌘ Read more
Email Forwarding Broken on iCloud
I have been getting occasional bounces from an iCloud+ Custom Domain email filter I have, which forwards certain emails I receive to wife. The first one I got looked like this:
<wife.email@mydomain.com>: host mx01.mail.icloud.com[17.57.156.30] said: 554 5.7.1
[HM07] Message rejected due to local policy. Please visit
https://support.apple.com/en-us/HT204137 (in reply to end of DATA command)
I sent an email to t … ⌘ Read more
Status 2025-07-21
Morning, computer! Spending my days off trying to figure things out.
Some of them will occur in this post. I think best when I’m writing,
after all.
I’m back from a short vacation since a couple of weeks. I’m still
going to take a few days off every week for a while. I need the break.
It’s been way too many 12-16 hour workdays. I’m nominally working 80%
(~6 hour days), so I figure I’ve been working a lot for free.
Yeah, well, I like the TKey project to succeed. The ideas behind it
have implicatio … ⌘ Read more
↳
In-reply-to
»
this is pretty cool, especially with a customized dmenu build:
⤋ Read More
@lyse@lyse.isobeef.org yesss it’s not my idea but it’s sooo fun here ngl like i should use it more!!
↳
In-reply-to
»
After many weeks and probably at least a hundred hours of research, discussions and in-person viewing, I think I've finally come up with my Final Choices (shortlist) of a Hybrid Camper / Caravan that I think will suit my family and that I'll enjoy (far less work for me to setup and teardown). The one at the top of the list I'm leaning towards os the SWAG SCT16 Family 4B Media #Camping #Campers
⤋ Read More
@prologic@twtxt.net that looks like a beautiful camper! What kind of truck do you have to pull it? That could be the next thing you might need to focus on. I mean, 2,800kg gross is not feather light!
↳
In-reply-to
»
Xfce does one thing very right: It stores its settings in plain-text XML files. This allows me to easily read, track, and maybe even distribute these settings to other machines.
⤋ Read More
@movq@www.uninformativ.de omg YAML is so demonic like it pretends to be readable and then THE SPACING. THE FUCKING SPACING
↳
In-reply-to
»
Xfce does one thing very right: It stores its settings in plain-text XML files. This allows me to easily read, track, and maybe even distribute these settings to other machines.
⤋ Read More
@kat@yarn.girlonthemoon.xyz I kind of like XML because it’s mostly well-defined and easy for humans to read (unlike YAML, which is a complete mess, imho) … and at the same time, it can get complicated really fast. 🫤 But at least it’s plain-text – that’s the important part in this case. 😅
ugh my TL’s once again doing the thing where it only shows like 5 twts
↳
In-reply-to
»
“” is my new favorite emoji.
⤋ Read More
@movq@www.uninformativ.de @lyse@lyse.isobeef.org i like this emoji too (it’s rhombus with question on my side)
I did a pretty intense workout this morning and afterwards I felt so good! I wish I remembered this whenever I feel like skipping training.
↳
In-reply-to
»
PSA:
⤋ Read More
setpriv on Linux supports Landlock.
@prologic@twtxt.net Yeah, it’s not a strong sandbox in jenny’s case, it could still read my SSH private key (in case of an exploit of some sort). But I still like it.
I think my main takeaway is this: Knowing that technologies like Landlock/pledge/unveil exist and knowing that they are very easy to use, will probably nudge me into writing software differently in the future.
jenny was never meant to be sandboxed, so it can’t make great use of it. Future software might be different.
(And this is finally a strong argument for static linking.)
↳
In-reply-to
»
This extension was turned off because it is no longer supported
⤋ Read More
Looks like here’s something wrong with Markdown parsing. 🤔 The original twt looks like this:
>This extension was turned off because it is no longer supported
Thanks Google.
This browser was uninstalled because it absolutely sucks!
So only the first line should be a quote.
Something happened with the frame rate of terminal emulators lately. It looks like there’s a trend to run at a high framerate now? I’m not sure exactly. This can be seen in VTE-based terminals like my xiate or XTerm on Wayland. foot and st, on the other hand, are fine.
My shell prompt and cursor look like this:
$ █
When I keep Enter pressed, I expect to see several lines like so:
$
$
$
$
$
$
$ █
With the affected terminal emulators, the lines actually show up in the following sequence. First, we have the original line:
$ █
Pressing Enter yields this as the next frame:
$
█
And then eventually this:
$
$ █
In other words, you can see the cursor jumping around very quickly, all the time.
Another example: Vim actually shows which key you just pressed in the bottom right corner. Keeping j pressed to scroll through a file means I get to see a j flashing rapidly now.
(I have no idea yet, why exactly XTerm in X11 is fine but flickering in Wayland.)
↳
In-reply-to
»
@movq Yeah, luckily, there is the suckless project. I couldn't live without dmenu!
⤋ Read More
@lyse@lyse.isobeef.org dmenu is a great example.
There have been several attempts at porting dmenu from X11 to Wayland. Well, not exactly “porting” it, more like rewriting it from scratch. Turns out: It’s not that easy.
dmenu is super fast and reliable. None of the Wayland rewrites are (at least none of the popular ones that I know of). They are either bloated and/or slow.
It takes a lot of discipline and restraint to write simple software and not blow up the codebase. This is much harder than people think. It’s a form of art, really.
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@prologic@twtxt.net Yeah, this really could use a proper definition or a “manifest”. 😅 Many of these ideas are not very wide spread. And I haven’t come across similar projects in all these years.
Let’s take the farbfeld image format as an example again. I think this captures the “spirit” quite well, because this isn’t even about code.
This is the entire farbfeld spec:
farbfeld is a lossless image format which is easy to parse, pipe and compress. It has the following format:
╔════════╤═════════════════════════════════════════════════════════╗
║ Bytes │ Description ║
╠════════╪═════════════════════════════════════════════════════════╣
║ 8 │ "farbfeld" magic value ║
╟────────┼─────────────────────────────────────────────────────────╢
║ 4 │ 32-Bit BE unsigned integer (width) ║
╟────────┼─────────────────────────────────────────────────────────╢
║ 4 │ 32-Bit BE unsigned integer (height) ║
╟────────┼─────────────────────────────────────────────────────────╢
║ [2222] │ 4x16-Bit BE unsigned integers [RGBA] / pixel, row-major ║
╚════════╧═════════════════════════════════════════════════════════╝
The RGB-data should be sRGB for best interoperability and not alpha-premultiplied.
(Now, I don’t know if your screen reader can work with this. Let me know if it doesn’t.)
I think these are some of the properties worth mentioning:
- The spec is extremely short. You can read this in under a minute and fully understand it. That alone is gold.
- There are no “knobs”: It’s just a single version, it’s not like there’s also an 8-bit color depth version and one for 16-bit and one for extra large images and one that supports layers and so on. This makes it much easier to implement a fully compliant program.
- Despite being so simple, it’s useful. I’ve used it in various programs, like my window manager, my status bars, some toy programs like “tuxeyes” (an Xeyes variant), or Advent of Code.
- The format does not include compression because it doesn’t need to. Just use something like bzip2 to get file sizes similar to PNG.
- It doesn’t cover every use case under the sun, but it does cover the most important ones (imho). They have discussed using something other than RGBA and decided it’s not worth the trouble.
- They refrained from adding extra baggage like metadata. It would have needlessly complicated things.
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@movq@www.uninformativ.de Yeah that’s why I’m striking this conversation with you 😅 Not only do I respect your opinion quite highly 🤣 But like you say (and I’ve read their philipshpy) it can be a bit “elitism” for sure. I’m genuinely interested in what we think of as software that “doesn’t suck”. Tb be honest I haven’t really put thought to paper myself, but I reckon if I did, I’d have some opinions/ideas…
↳
In-reply-to
»
The lack of suckless-like simple, hackable software these days is appalling.
⤋ Read More
@prologic@twtxt.net Hm, I wouldn’t say that. Go code could fall into that category as well.
Maybe this topic could use a blog post / article, that explains what it’s about. I’m finding it hard to really define what “suckless-like software” is. 🤔 (Their own philosophy focuses too much on elitism, if you ask me.)
My workout for today is done! I never feel like starting but when I do it it always feels great.
↳
In-reply-to
»
A good blog post that makes some good points: Can I ethically use LLMs?
⤋ Read More
@eldersnake@we.loveprivacy.club Yeah well when you put it like that 🤣
↳
In-reply-to
»
A good blog post that makes some good points: Can I ethically use LLMs?
⤋ Read More
I’ve been playing around with AI at home over the past few months and building my own neural networks from scratch (in Go) with genetic algorithms
Oh, is that all 🤣
That sounds like some intensive ‘playing around’ haha
The lack of suckless-like simple, hackable software these days is appalling.
↳
In-reply-to
»
A good blog post that makes some good points: Can I ethically use LLMs?
⤋ Read More
@eldersnake@we.loveprivacy.club Yeah for sure! The thing that annoys me about a lot of this, is the sheer fact you can’t really self-host let alone self-train these things I’ve been playing around with AI at home over the past few months and building my own neural networks from scratch (in Go) with genetic algorithms on a few tasks and training sets, but man it’s hard™ 🤣 I feel like we’re doing something wrong here…
↳
In-reply-to
»
A good blog post that makes some good points: Can I ethically use LLMs?
⤋ Read More
@eldersnake@we.loveprivacy.club This was an interesting read for sure! 👍 I don’t think it had anything I hadn’t already considered in terms of the ethical/moral points of view. I’m not sure where I stand myself either to be honest. I’ve forced myself to get familiar with the ecosystem and tooling, because in my line of work as a tech lead (staff engineer in sre) you don’t want to be that one guy that ya know 😉 Ethically/Morally though, I’m definitely with the sentiment of this post 😅 Much like the whole Crypto hype yaers back (if y’all remember?!) this is also one of the most energy hungry pieces of “tech” (if you can call it that?) in a while. Then there’s these other issues “stealing people’s work”, “reliance is causing humans to become cognitively weak and neural connections to shrink”, to name a few…
↳
In-reply-to
»
This aggressive auto-logout on my bank’s website …
⤋ Read More
I hear you, @movq@www.uninformativ.de! :‘-(
At work, too. For a few weeks now when I try to log into this horrible Outlook web intershit (Because why would they fix the Evolution integration?! It’s cactus for well over a year now. Probably more like two.), it forwards me to the corporate weblogin, I enter my credentials, even do the bloody MFA crap and get redirected back to Outlook. “Loading mailbox…” “Please wait for us to log you out, do not close this window while this process is underway.” Fuck you! I have to delete the cookies for this damn domain each and every fucking time. Otherwise, this goes in circles forever. I tried the game for 15 minutes, no joke.
But wait, there’s more! Why just fuck it up only a little bit? This week I get logged out at the middle of the day. Every. Single. Day. Not even close to eight hours since I started, no. What the hell!? I reckon I just don’t even bother reauthenticating anymore in the arvo. No more e-mails for Lyse after lunch. Fuck it. It’s just distraction, anyway, right?!
↳
In-reply-to
»
TIL: The logo of
⤋ Read More
sudo is a sandwich. 🫠 https://www.sudo.ws/
@movq@www.uninformativ.de @bender@twtxt.net I never saw that. Neither the website nor the logo. I like the old one more, although I have to admit the story behind the new one is actually really cool: https://www.sudo.ws/about/logo/
/ME feels like melting fater than a bowl of Icecream. Weeeeee… 🫠😅
↳
In-reply-to
»
As promised, here's some photos of love you!! camping trip to Canarcon George in QLD, Australia. Media Media Media
⤋ Read More
@prologic@twtxt.net I like the last two, on the first three you sent. I looked up “Canarvon Gorge”, and read more about it. Thanks for introducing me to it!
Just realized: One of the reasons why I don’t like “flat UIs” is that they look broken to me. Like the program has a bug, missing pixmaps or whatever.
Take this for example:
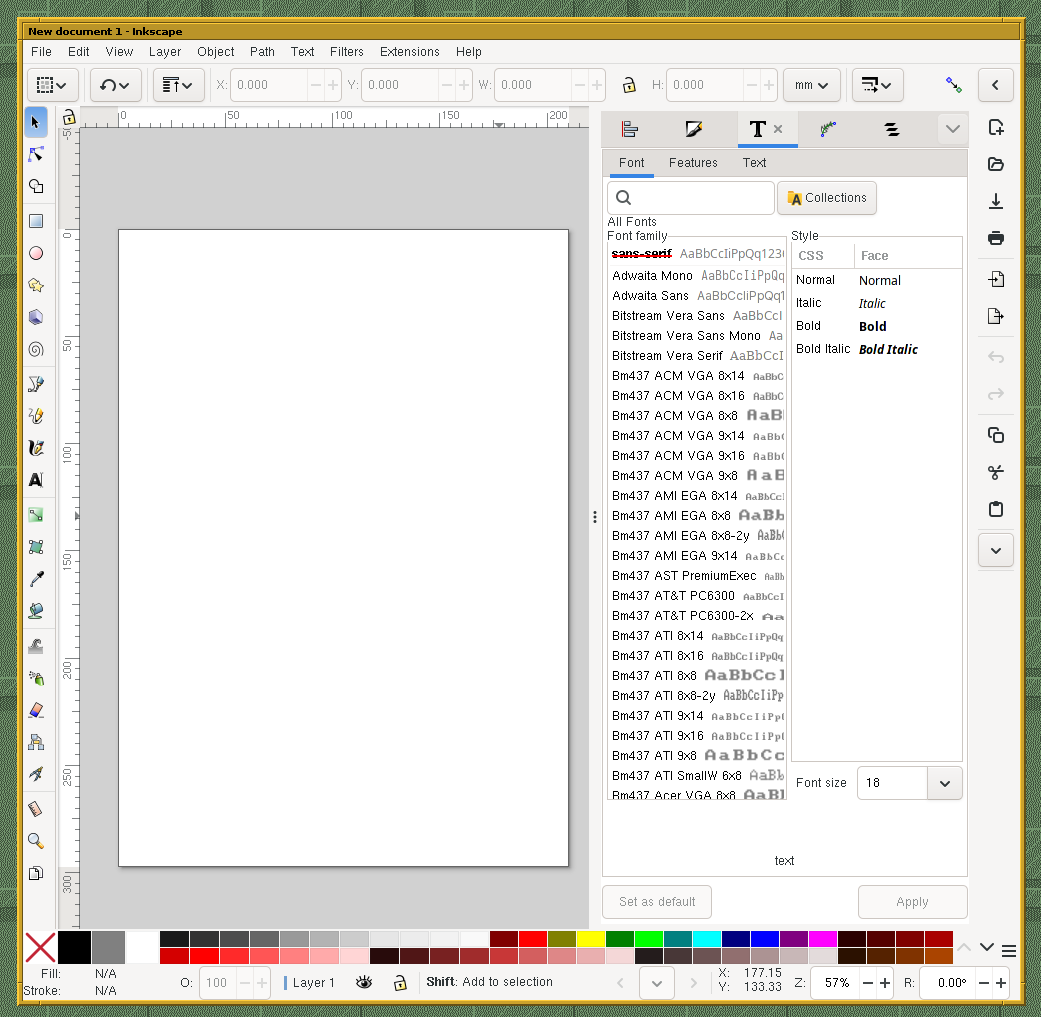
I’m talking about this area specifically:
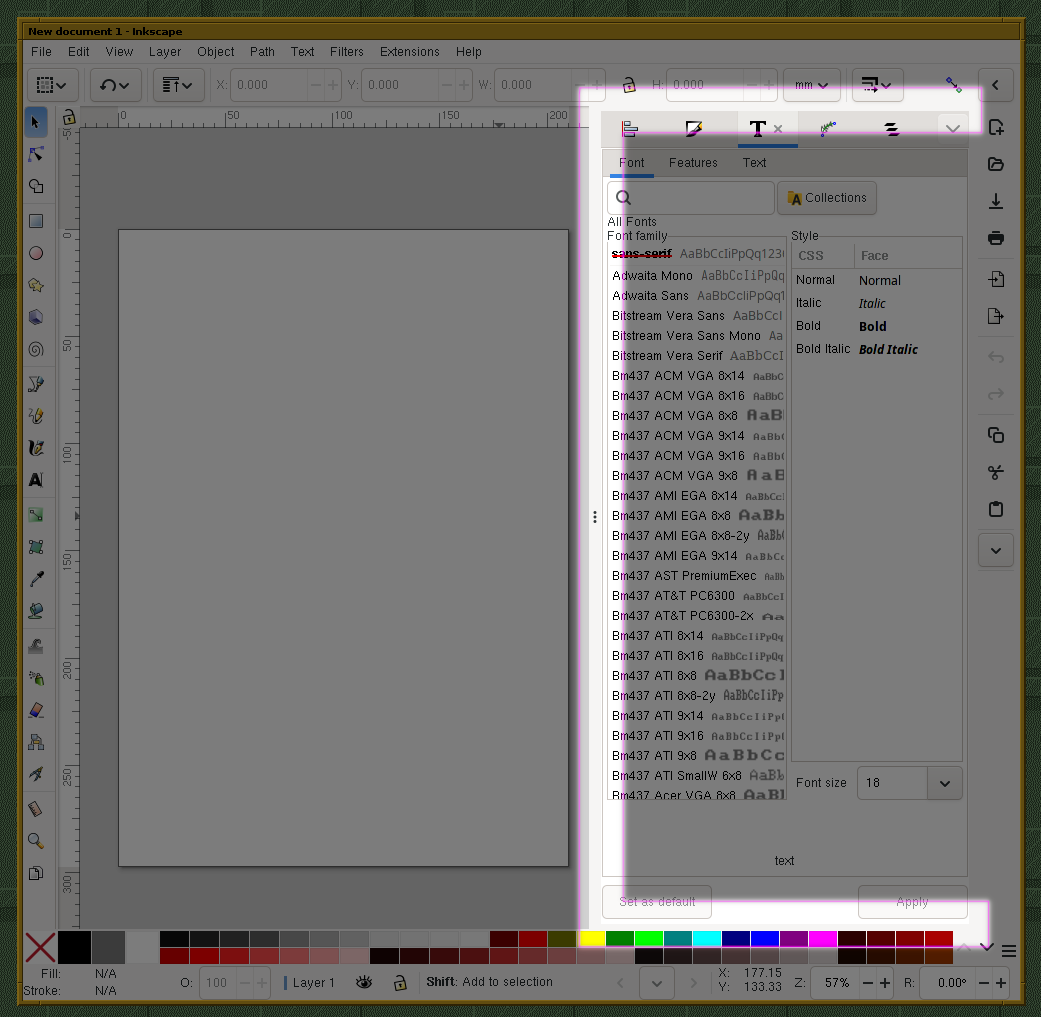
One UI element ends and the other one begins – no “transition” between them.
The style of old UIs like these two is deeply ingrained into my brain:
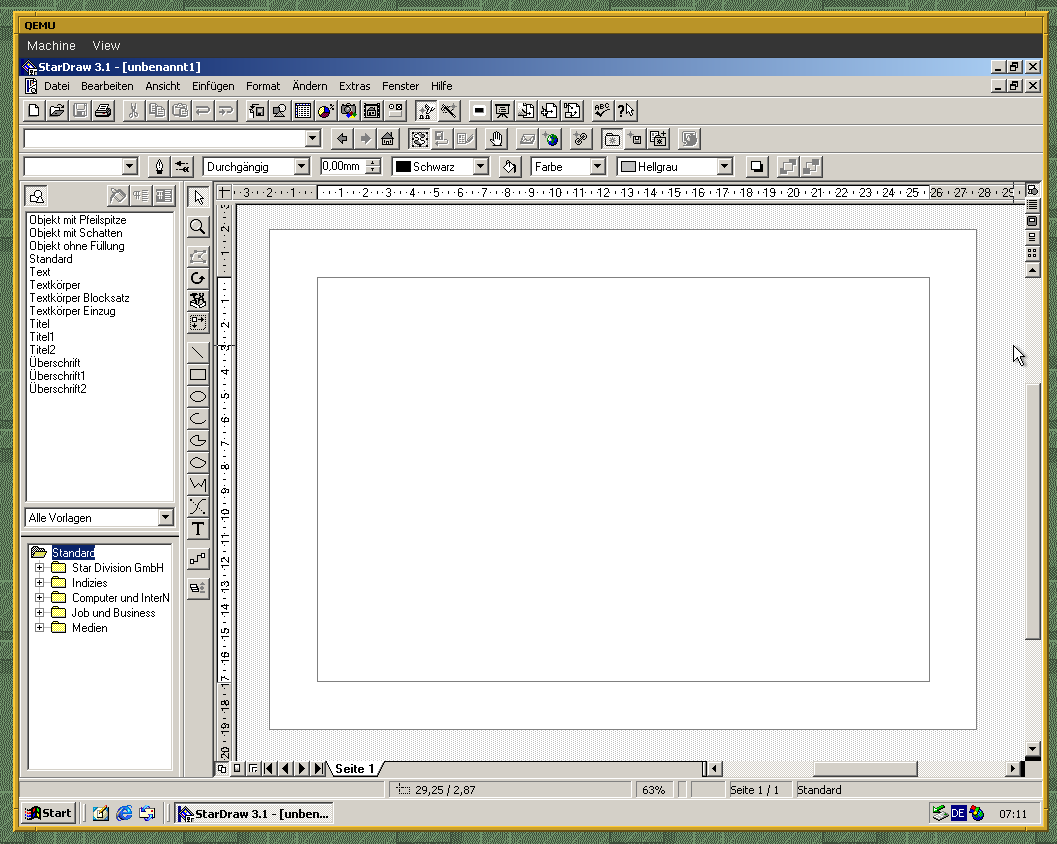
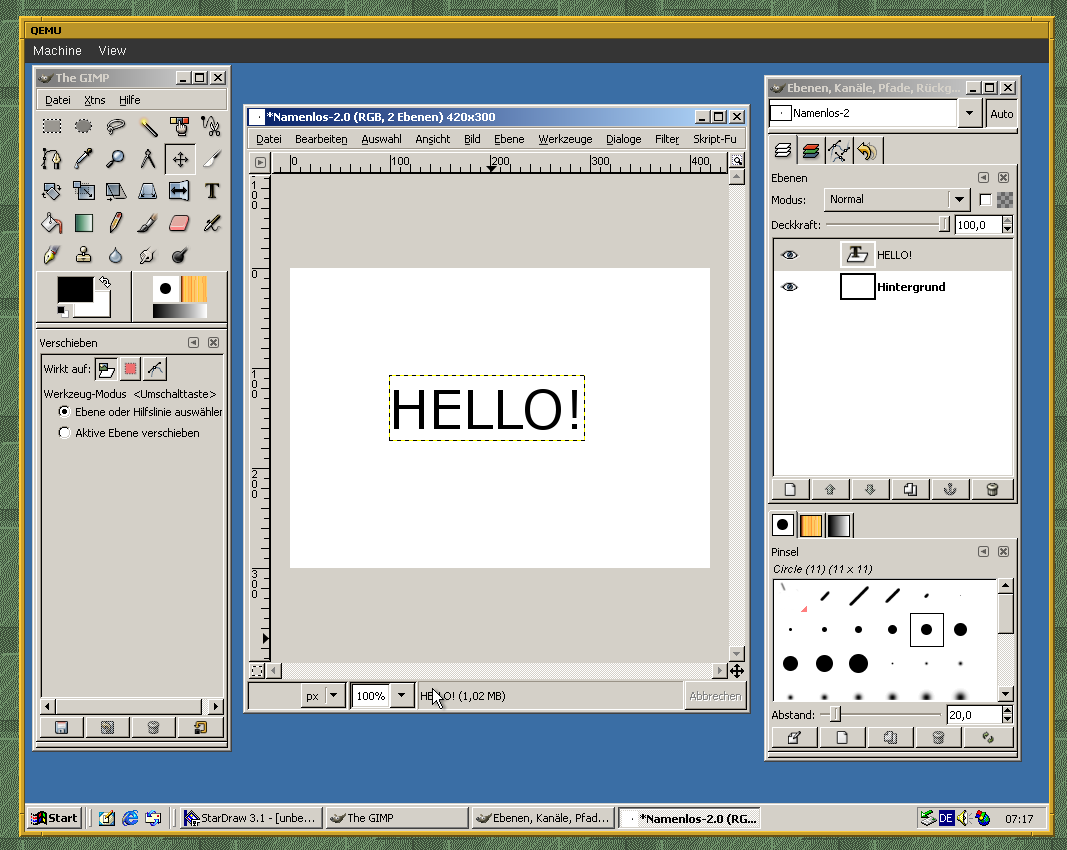
When all these little elements (borders, handles, even just simple lines, …) are no longer present, then the program looks buggy and broken to me. And I’m not sure if I’ll ever be able to un-learn that.
@lyse@lyse.isobeef.org Wow. Just like Skyrim! 😃
↳
In-reply-to
»
went to vote. got told i can't vote because i'm not registered. handed a form to fill out that i later learn is not in english.
⤋ Read More
Anyone that the Pigs don’t like sure is the perfect candidate. Without fail.
↳
In-reply-to
»
went to vote. got told i can't vote because i'm not registered. handed a form to fill out that i later learn is not in english.
⤋ Read More
Happy for you! Mamdani looks like he will be good for NYC.
i love pinkpantheress so much she’s so cute and fun and tapped into every aesthetic and dance music sound i love. if you like house and garage and D&B music, check her out!!!! she absolutely knows her shit too btw she’s sampled basement jaxx and adam F
https://www.youtube.com/watch?v=Xo_lPnBlfto
https://www.youtube.com/watch?v=TFWXqLSr4ZM
went to vote. got told i can’t vote because i’m not registered. handed a form to fill out that i later learn is not in english.
go home and find out the problem is widespread among young voters like me.
fuck this country.
↳
In-reply-to
»
I did a “lecture”/“workshop” about this at work today. 16-bit DOS, real mode. 💾 Pretty cool and the audience (devs and sysadmins) seemed quite interested. 🥳
⤋ Read More
They’re all talks, not real hands-on trainings like you did.
I love listening to good, well-structured talks. Problem is, not everybody is a good speaker and many screw it up. 🥴 I’m certainly not a great speaker, which is why I gravitate more towards “workshops”, in the hopes that people ask questions and discussions arise. Doesn’t always work out. 🤣 At the very least, I almost always have some other person connect to the projector/beamer/screenshare and then they do the stuff – this avoids me being wwwwaaaaaaaaayyyy too fast.
We are usually drowned in stress and tight deadlines, hence events like today are super rare … We used to do it more often until ~10 years ago.
Once a year the security guys organize a really great hacking event, though.
Oh dear, I’d love to participate in that. 🤯 That sounds like a lot of fun. (Why don’t we do this?!)
I did a “lecture”/“workshop” about this at work today. 16-bit DOS, real mode. 💾 Pretty cool and the audience (devs and sysadmins) seemed quite interested. 🥳
- People used the Intel docs to figure out the instruction encodings.
- Then they wrote a little DOS program that exits with a return code and they used uhex in DOSBox to do that. Yes, we wrote a COM file manually, no Assembler involved. (Many of them had never used DOS before.)
- DEBUG from FreeDOS was used to single-step through the program, showing what it does.
- This gets tedious rather quickly, so we switched to SVED from SvarDOS for writing the rest of the program in Assembly language. nasm worked great for us.
- At the end, we switched to BIOS calls instead of DOS syscalls to demonstrate that the same binary COM file works on another OS. Also a good opportunity to talk about bootloaders a little bit.
- (I think they even understood the basics of segmentation in the end.)
The 8086 / 16-bit real-mode DOS is a great platform to explain a lot of the fundamentals without having to deal with OS semantics or executable file formats.
Now that was a lot of fun. 🥳 It’s very rare that we do something like this, sadly. I love doing this kind of low-level stuff.
Okay, here’s a thing I like about Rust: Returning things as Option and error handling. (Or the more complex Result, but it’s easier to explain with Option.)
fn mydiv(num: f64, denom: f64) -> Option<f64> {
// (Let’s ignore precision issues for a second.)
if denom == 0.0 {
return None;
} else {
return Some(num / denom);
}
}
fn main() {
// Explicit, verbose version:
let num: f64 = 123.0;
let denom: f64 = 456.0;
let wrapped_res = mydiv(num, denom);
if wrapped_res.is_some() {
println!("Unwrapped result: {}", wrapped_res.unwrap());
}
// Shorter version using "if let":
if let Some(res) = mydiv(123.0, 456.0) {
println!("Here’s a result: {}", res);
}
if let Some(res) = mydiv(123.0, 0.0) {
println!("Huh, we divided by zero? This never happens. {}", res);
}
}
You can’t divide by zero, so the function returns an “error” in that case. (Option isn’t really used for errors, IIUC, but the basic idea is the same for Result.)
Option is an enum. It can have the value Some or None. In the case of Some, you can attach additional data to the enum. In this case, we are attaching a floating point value.
The caller then has to decide: Is the value None or Some? Did the function succeed or not? If it is Some, the caller can do .unwrap() on this enum to get the inner value (the floating point value). If you do .unwrap() on a None value, the program will panic and die.
The if let version using destructuring is much shorter and, once you got used to it, actually quite nice.
Now the trick is that you must somehow handle these two cases. You must either call something like .unwrap() or do destructuring or something, otherwise you can’t access the attached value at all. As I understand it, it is impossible to just completely ignore error cases. And the compiler enforces it.
(In case of Result, the compiler would warn you if you ignore the return value entirely. So something like doing write() and then ignoring the return value would be caught as well.)
We really are bouncing back and forth between flat UIs and beveled UIs. I mean, this is what old X11 programs looked like:
Good luck figuring out which of these UI elements are click-able – unless you examine every pixel on the screen.
↳
In-reply-to
»
update on tux racer: ofc it doesn't run on modern linux LMFAOOOOOOO i'm installing red hat in a VM right now
⤋ Read More
@kat@yarn.girlonthemoon.xyz I like the animations in your version much better than the ones from ExtremeTuxRacer. 😊 And there’s no little dance at the end of a race!
Felt the need to make this stupid reference - nobody will get, most likely. Feel free to guess (the file name and todays date, are both a hint), any other notes and opinions appreciated too, idk if I ever drew a standing one, from the front, before.