↳
In-reply-to
»
Oh boy, I absolutely hate this stupid trend of not writing changelogs anymore! Why the fuck would one seriously consider it to be a viable option to just let some shitty bot spew all merge requests on a goddamn GitHub release?! First of all, these merge request titles suck balls. The order of the changes in this "changelog" is completely random (well, probably merge time, which is as useless as the dick on the Pope). They are not grouped by anything at all. Additions, changes, removals, deprecations, etc. randomly mixed up in one giant list. And then "Add feature X", seventeen kilometers further down "Revert 'Add feature X'". Fuck you! Don't include this shit in the first place!
⤋ Read More
Updated draft: http://movq.de/blog/drafts/changelog/POSTING-en.html
I’ll probably publish this later today. Or maybe not at all. It’s one of those topics that might cause outrage because I’m getting it all wrong. 🤪
↳
In-reply-to
»
Oh boy, I absolutely hate this stupid trend of not writing changelogs anymore! Why the fuck would one seriously consider it to be a viable option to just let some shitty bot spew all merge requests on a goddamn GitHub release?! First of all, these merge request titles suck balls. The order of the changes in this "changelog" is completely random (well, probably merge time, which is as useless as the dick on the Pope). They are not grouped by anything at all. Additions, changes, removals, deprecations, etc. randomly mixed up in one giant list. And then "Add feature X", seventeen kilometers further down "Revert 'Add feature X'". Fuck you! Don't include this shit in the first place!
⤋ Read More
@lyse@lyse.isobeef.org This is the draft so far, let me know what you think: https://movq.de/blog/drafts/changelog/POSTING-en.html
The 15 standout draft prospects at this year’s AFL under-18 championships
Recruiters will be out in force to try to unearth the AFL’s next stars when the under-18 championships begin this weekend across the country. ⌘ Read more
Street Fighter Movie Gets Encouraging Update After a ‘Pretty Rough’ Script
Street Fighter 6‘s director just revealed why the movie‘s script needed two years of rewrites. Takayuki Nakayama shared what went wrong with the first draft of the upcoming adaptation. Why the Street Fighter movie underwent two years of rewrites Street Fighter 6 director Takayuki Nakayama told Dexerto that he spent two years helping rewrite the […]
The post [Street Fighter Movie Gets Encouraging Update Afte … ⌘ Read more
Seattle Enacts Year-Long Ban On New AI Datacenters
Seattle has enacted a one-year moratorium on new datacenters, making it the largest U.S. city to do so as the backlash against AI infrastructure grows across the country. The city council voted unanimously in favor of the ban. The Guardian reports: Lawmakers have framed the pause as an opportunity to draft regulations specifically targeting the electricity-hungry datacenters bei … ⌘ Read more
First draft of a file selection popup / widget:
https://movq.de/v/0955149868/vid-1781094010.mp4
Also makes use of the new Table widget.
Meridian rejects Energy Minister’s concerns in late-stage fast-track submission
As Meridian Energy welcomes the fast-track panel’s draft decision to ease access restrictions on Lake Pūkaki hydro storage for a three-year period, new documents show it rejected concerns raised by the Energy Minister over electricity security of sup … ⌘ Read more
Tom Holland Reveals Surprising Writer Involved With Spider-Man 4’s Final Draft
Spider-Man 4‘s final draft involved a writer many didn’t know about. Tom Holland just revealed the surprising writer who helped with Spider-Man: Brand New Day‘s last-minute script changes. Justin Kuritzkes was involved with Spider-Man 4’s final draft So far, Chris McKenna and Erik Sommers have been credited as the writers of the fourth Spider-Man installment. […]
The post [Tom Holland Reveals Su … ⌘ Read more
Commerce Commission moves to cap Visa, Mastercard business card fees
The Commerce Commission is proposing new interchange fee caps on Mastercard and Visa commercial credit cards that will lower costs for businesses by some $40 million a year.
The draft decision said New Zealand businesses paid about $125m a year in interchange fees to accept Mastercard and Visa commercial credit cards. ⌘ Read more
Anthropic confidentially submits draft S-1 to the SEC
Article URL: https://www.anthropic.com/news/confidential-draft-s1-sec
Comments URL: https://news.ycombinator.com/item?id=48358646
Points: 8
# Comments: 0 ⌘ Read more
↳
In-reply-to
»
I’ve started collecting reasons against AI usage here, so I don’t have to repeat myself all the time:
⤋ Read More
@lyse@lyse.isobeef.org Thanks! There are a few points in there that I’ll add to my list.
Your very first point is obviously crucial. “Writing code” is just the means to an end for many people and they don’t really care about it or like it, so they love AI. I had this in another draft (it refers to the other list I posted):
https://movq.de/v/614f14c3ef/ramble.txt
And this right here is so important:
simplicity is the real art and much harder to achieve.
Finding an elegant, simple solution is waaaaaaaaaaaaaaaaaay harder than anything else. And here’s the thing: I don’t get why nerds/techies don’t get “nerd-sniped” by this. A lot of people love building big stuff and then brag about being clever/competent because they were able to build that big thing – but once you realize that this approach is the lazy one, shouldn’t you make finding the elegant solution your goal? Doesn’t that give you more bragging rights?
(Am I being clear? Do you understand what I mean? 😅)
PCIe 8.0 Spec Draft 0.5 Released For 1TB/s Bi-Directional x16 Bandwidth
The PCI-SIG today held a briefing around PCIe 8.0 that follows the PCIe 7.0 specification that was released to members last June… ⌘ Read more
South Africa’s Draft AI Policy Withdrawn Due to ‘Fictitious’ AI-Generated Citations
An official in South Africa withdrew a draft of the country’s national AI policy, reports a local newspaper, “after it was found the draft policy was compiled using AI, which cited academic articles that were ‘fictitious’.”
Earlier this month, minister in the Presidency Khumbudzo Ntshavheni announced cabinet had … ⌘ Read more
VideoLAN Publishes Dav2d For Open-Source AV2 Decoder
While the Alliance For Open Media had been aiming for the AV2 release by the end of 2025, as of right now the AV2 specification remains in a draft status. VideoLAN developers though for months have already been working on dav2d as an open-source AV2 decoder and that code was published this weekend… ⌘ Read more
FreeBSD Laptop Project Hopes To Port Newer Linux Graphics Drivers This Year
Developers working on the FreeBSD laptop initiative to make the FreeBSD operating system more suitable for running on modern laptop hardware have drafted their road-map of further action items they hope to accomplish in 2026… ⌘ Read more
EPA Flags Microplastics, Pharmaceuticals As Contaminants In Drinking Water
An anonymous reader quotes a report from NPR: Responding to public health concerns about microplastics and pharmaceuticals in the nation’s drinking water, the Trump administration for the first time has placed them on a draft list of contaminants maintained by the Environmental Protection Agency. The EPA announced the move Thurs … ⌘ Read more
Life With AI Causing Human Brain ‘Fry’
fjo3 shares a report from France 24: Too many lines of code to analyze, armies of AI assistants to wrangle, and lengthy prompts to draft are among the laments by hard-core AI adopters. Consultants at Boston Consulting Group (BCG) have dubbed the phenomenon “AI brain fry,” a state of mental exhaustion stemming “from the excessive use or supervision of artificial intelligence tools, pushed beyond our co … ⌘ Read more
Roblox, YouTube caught in major children’s privacy overhaul
A new draft code would give children the right to demand deletion of their data and ban “dark patterns” designed to trick them into sharing more. ⌘ Read more
Austria Plans Social Media Ban For Under-14s
Austria plans to restrict under-14s from using social media platforms over concerns about addictive algorithms and harmful content. The government says draft legislation should be ready by the end of June, though details around enforcement and age verification have yet to be finalized. The BBC reports: Announcing the plans, Vice-Chancellor Andreas Babler of the Social Democrats said th … ⌘ Read more
AlmaLinux To Focus On Increased Testing & Other Goals For 2026
Developers behind AlmaLinux as this popular community alternative to Red Hat Enterprise Linux (RHEL) have drafted some new goals for 2026… ⌘ Read more
Editor At 184-Year-Old Ohio Newspaper Pushes To Let AI Draft News Articles
An anonymous reader quotes a report from the Washington Post: The Plain Dealer, Cleveland’s largest newspaper, has begun to feature a new byline. On recent articles about an ice carving festival, a medical research discovery and a roaming pack of chicken-slaying dogs, a reporter’s name is paired with the words “Advance Local E … ⌘ Read more
Ohio Newspaper Removes Writing From Reporters’ Jobs, Hands It To an ‘AI Rewrite Specialist’
Cleveland.com, the digital arm of Ohio’s Plain Dealer newspaper, has removed writing from the workloads of certain reporters and handed that job to what editor Chris Quinn calls an “AI rewrite specialist” who turns reporter-gathered material into article drafts.
The reporters on these beats – co … ⌘ Read more
White House Eyes Data Center Agreements Amid Energy Price Spikes
An anonymous reader shares a report: The Trump administration wants some of the world’s largest technology companies to publicly commit to a new compact governing the rapid expansion of AI data centers, according to two administration officials granted anonymity to discuss private conversations.
A draft of the compact obtained by POLITICO lay … ⌘ Read more
Kernel Community Drafts a Plan For Replacing Linus Torvalds
The Linux kernel community has formalized a continuity plan for the day Linus Torvalds eventually steps aside, defining how the process would work to replace him as the top-level maintainer. ZDNet’s Steven Vaughan-Nichols reports: The new “plan for a plan,” drafted by longtime kernel contributor Dan Williams, was discussed at the latest Linux Kernel Maint … ⌘ Read more
DOT Plans To Use Google Gemini AI To Write Regulations
The Trump administration is planning to use AI to write federal transportation regulations, ProPublica reported on Monday, citing the U.S. Department of Transportation records and interviews with six agency staffers. From the report: The plan was presented to DOT staff last month at a demonstration of AI’s “potential to revolutionize the way we draft rulemakings,” a … ⌘ Read more
Fedora Games Lab Approved To Switch To KDE Plasma, Become A Better Linux Gaming Showcase
Back in December we reported on drafted plans for revitalizing Fedora Games Lab to be a modern Linux gaming showcase. This Fedora Labs initiative has featured some open-source games paired with an Xfce desktop while moving forward they are looking to better position it as a modern Linux gaming showcase… ⌘ Read more
France Targets Australia-Style Social Media Ban For Children Next Year
An anonymous reader quotes a report from the Guardian: France intends to follow Australia and ban social media platforms for children from the start of the 2026 academic year. A draft bill preventing under-15s from using social media will be submitted for legal checks and is expected to be debated in parliament early in the new year. … ⌘ Read more
China Drafts World’s Strictest Rules To End AI-Encouraged Suicide, Violence
An anonymous reader quotes a report from Ars Technica: China drafted landmark rules to stop AI chatbots from emotionally manipulating users, including what could become the strictest policy worldwide intended to prevent AI-supported suicides, self-harm, and violence. China’s Cyberspace Administration proposed the rules on Saturday. … ⌘ Read more
North Melbourne still confident of landing former AFLW number one pick
North Melbourne have been unable to trade for Kristie-Lee Weston-Turner but the two-time defending AFLW premiers are still confident they’ll secure the former number one draft pick. ⌘ Read more
Bulldogs’ top AFLW draft pick wants to join Kangaroos
The Kangaroos’ domination of the AFLW is set to be given another boost, with a former number one draft pick confirming she wants to head to North. ⌘ Read more
Putin says US-Ukraine text could form basis for peace agreement
The US and Ukraine are set to hold further talks about a draft peace deal to bring to an end the conflict. ⌘ Read more
All my newly added test cases failed, that movq thankfully provided in https://git.mills.io/yarnsocial/twtxt.dev/pulls/28#issuecomment-20801 for the draft of the twt hash v2 extension. The first error was easy to see in the diff. The hashes were way too long. You’ve already guessed it, I had cut the hash from the twelfth character towards the end instead of taking the first twelve characters: hash[12:] instead of hash[:12].
After fixing this rookie mistake, the tests still all failed. Hmmm. Did I still cut the wrong twelve characters? :-? I even checked the Go reference implementation in the document itself. But it read basically the same as mine. Strange, what the heck is going on here?
Turns out that my vim replacements to transform the Python code into Go code butchered all the URLs. ;-) The order of operations matters. I first replaced the equals with colons for the subtest struct fields and then wanted to transform the RFC 3339 timestamp strings to time.Date(…) calls. So, I replaced the colons in the time with commas and spaces. Hence, my URLs then also all read https, //example.com/twtxt.txt.
But that was it. All test green. \o/
White House Prepares Executive Order To Block State AI Laws
An anonymous reader quotes a report from Politico: The White House is preparing to issue an executive order as soon as Friday that tells the Department of Justice and other federal agencies to prevent states from regulating artificial intelligence, according to four people familiar with the matter and a leaked draft of the order obtained by POLITICO. The dr … ⌘ Read more
Spot the difference: Leaked WA gas report changed before it was tabled in parliament
The report was tabled in parliament on Tuesday afternoon after the draft version, meant to be a confidential cabinet document, was leaked. But there are notable changes. ⌘ Read more
Plan for children to face life sentences draws wave of condemnation
Premier Jacinta Allan revealed that complex legislation was still being drafted, with a bill to be introduced to parliament by the end of this year. ⌘ Read more
↳
In-reply-to
»
@bender Thanks for this illustration, it completely “misunderstood” everything I wrote and confidently spat out garbage. 👌
⤋ Read More
@prologic@twtxt.net Let’s go through it one by one. Here’s a wall of text that took me over 1.5 hours to write.
The criticism of AI as untrustworthy is a problem of misapplication, not capability.This section says AI should not be treated as an authority. This is actually just what I said, except the AI phrased/framed it like it was a counter-argument.
The AI also said that users must develop “AI literacy”, again phrasing/framing it like a counter-argument. Well, that is also just what I said. I said you should treat AI output like a random blog and you should verify the sources, yadda yadda. That is “AI literacy”, isn’t it?
My text went one step further, though: I said that when you take this requirement of “AI literacy” into account, you basically end up with a fancy search engine, with extra overhead that costs time. The AI missed/ignored this in its reply.
Okay, so, the AI also said that you should use AI tools just for drafting and brainstorming. Granted, a very rough draft of something will probably be doable. But then you have to diligently verify every little detail of this draft – okay, fine, a draft is a draft, it’s fine if it contains errors. The thing is, though, that you really must do this verification. And I claim that many people will not do it, because AI outputs look sooooo convincing, they don’t feel like a draft that needs editing.
Can you, as an expert, still use an AI draft as a basis/foundation? Yeah, probably. But here’s the kicker: You did not create that draft. You were not involved in the “thought process” behind it. When you, a human being, make a draft, you often think something like: “Okay, I want to draw a picture of a landscape and there’s going to be a little house, but for now, I’ll just put in a rough sketch of the house and add the details later.” You are aware of what you left out. When the AI did the draft, you are not aware of what’s missing – even more so when every AI output already looks like a final product. For me, personally, this makes it much harder and slower to verify such a draft, and I mentioned this in my text.
Skill Erosion vs. Skill EvolutionYou, @prologic@twtxt.net, also mentioned this in your car tyre example.
In my text, I gave two analogies: The gym analogy and the Google Translate analogy. Your car tyre example falls in the same category, but Gemini’s calculator example is different (and, again, gaslight-y, see below).
What I meant in my text: A person wants to be a programmer. To me, a programmer is a person who writes code, understands code, maintains code, writes documentation, and so on. In your example, a person who changes a car tyre would be a mechanic. Now, if you use AI to write the code and documentation for you, are you still a programmer? If you have no understanding of said code, are you a programmer? A person who does not know how to change a car tyre, is that still a mechanic?
No, you’re something else. You should not be hired as a programmer or a mechanic.
Yes, that is “skill evolution” – which is pretty much my point! But the AI framed it like a counter-argument. It didn’t understand my text.
(But what if that’s our future? What if all programming will look like that in some years? I claim: It’s not possible. If you don’t know how to program, then you don’t know how to read/understand code written by an AI. You are something else, but you’re not a programmer. It might be valid to be something else – but that wasn’t my point, my point was that you’re not a bloody programmer.)
Gemini’s calculator example is garbage, I think. Crunching numbers and doing mathematics (i.e., “complex problem-solving”) are two different things. Just because you now have a calculator, doesn’t mean it’ll free you up to do mathematical proofs or whatever.
What would have worked is this: Let’s say you’re an accountant and you sum up spendings. Without a calculator, this takes a lot of time and is error prone. But when you have one, you can work faster. But once again, there’s a little gaslight-y detail: A calculator is correct. Yes, it could have “bugs” (hello Intel FDIV), but its design actually properly calculates numbers. AI, on the other hand, does not understand a thing (our current AI, that is), it’s just a statistical model. So, this modified example (“accountant with a calculator”) would actually have to be phrased like this: Suppose there’s an accountant and you give her a magic box that spits out the correct result in, what, I don’t know, 70-90% of the time. The accountant couldn’t rely on this box now, could she? She’d either have to double-check everything or accept possibly wrong results. And that is how I feel like when I work with AI tools.
Gemini has no idea that its calculator example doesn’t make sense. It just spits out some generic “argument” that it picked up on some website.
3. The Technical and Legal Perspective (Scraping and Copyright)The AI makes two points here. The first one, I might actually agree with (“bad bot behavior is not the fault of AI itself”).
The second point is, once again, gaslighting, because it is phrased/framed like a counter-argument. It implies that I said something which I didn’t. Like the AI, I said that you would have to adjust the copyright law! At the same time, the AI answer didn’t even question whether it’s okay to break the current law or not. It just said “lol yeah, change the laws”. (I wonder in what way the laws would have to be changed in the AI’s “opinion”, because some of these changes could kill some business opportunities – or the laws would have to have special AI clauses that only benefit the AI techbros. But I digress, that wasn’t part of Gemini’s answer.)
tl;drExcept for one point, I don’t accept any of Gemini’s “criticism”. It didn’t pick up on lots of details, ignored arguments, and I can just instinctively tell that this thing does not understand anything it wrote (which is correct, it’s just a statistical model).
And it framed everything like a counter-argument, while actually repeating what I said. That’s gaslighting: When Alice says “the sky is blue” and Bob replies with “why do you say the sky is purple?!”
But it sure looks convincing, doesn’t it?
Never againThis took so much of my time. I won’t do this again. 😂
↳
In-reply-to
»
For the innocent bystanders (because I know that I won’t change @bender’s opinion):
⤋ Read More
@movq@www.uninformativ.de Gemini liked your opinion very much. Here is how it countered:
1. The User Perspective (Untrustworthiness)The criticism of AI as untrustworthy is a problem of misapplication, not capability.
- AI as a Force Multiplier: AI should be treated as a high-speed drafting and brainstorming tool, not an authority. For experts, it offers an immense speed gain, shifting the work from slow manual creation to fast critical editing and verification.
- The Rise of AI Literacy: Users must develop a new skill—AI literacy—to critically evaluate and verify AI’s probabilistic output. This skill, along with improving citation features in AI tools, mitigates the “gaslighting” effect.
The fear of skill loss is based on a misunderstanding of how technology changes the nature of work; it’s skill evolution, not erosion.
- Shifting Focus to High-Level Skills: Just as the calculator shifted focus from manual math to complex problem-solving, AI shifts the focus from writing boilerplate code to architectural design and prompt engineering. It handles repetitive tasks, freeing humans for creative and complex challenges.
- Accessibility and Empowerment: AI serves as a powerful democratizing tool, offering personalized tutoring and automation to people who lack deep expertise. While dependency is a risk, this accessibility empowers a wider segment of the population previously limited by skill barriers.
The legal and technical flaws are issues of governance and ethical practice, not reasons to reject the core technology.
- Need for Better Bot Governance: Destructive scraping is a failure of ethical web behavior and can be solved with better bot identification, rate limits, and protocols (like enhanced
robots.txt). The solution is to demand digital citizenship from AI companies, not to stop AI development.
Advanced Documentation Retrieval on FreeBSD
I thought it might be nice to repost this considering the date.
When I originally wrote this I was planning an interview with Michael W. Lucas and at some point “leaked” this draft article to him. After about a day I got the email equivalent of a spit take and a ton of laughter.
Enjoy!
Russia Moves to Year-Round Military Draft Amid Wartime Manpower Needs ⌘ Read more
Turkish government drafts anti-LGBTQ+ laws threatening prison for trans people and same-sex couples ⌘ Read more
How to Add MCP Servers to Claude Code with Docker MCP Toolkit
AI coding assistants have evolved from simple autocomplete tools into full development partners. Yet even the best of them, like Claude Code, can’t act directly on your environment. Claude Code can suggest a database query, but can’t run it. It can draft a GitHub issue, but can’t create it. It can write a Slack message,… ⌘ Read more
Pretty happy with my zs-blog-template starter kit for creating and maintaining your own blog using zs 👌 Demo of what the starter kit looks like here – Basic features include:
- Clean layout & typography
- Chroma code highlighting (aligned to your site palette)
- Accessible copy-code button
- “On this page” collapsible TOC
- RSS, sitemap, robots
- Archives, tags, tag cloud
- Draft support (hidden from lists/feeds)
- Open Graph (OG) & Twitter card meta (default image + per-post overrides)
- Ready-to-use 404 page
As well as custom routes (redirects, rewrites, etc) to support canonical URLs or redirecting old URLs as well as new zs external command capability itself that now lets you do things like:
$ zs newpost
to help kick-start the creation of a new post with all the right “stuff”™ ready to go and then pop open your $EEDITOR 🤞
TNO Threading (draft):
Each origin feed numbers new threads (tno:N). Replies carry both (tno:N) and (ofeed:<origin-url>). Thread identity = (ofeed, tno).
- Roots:
(tno:N)(implicitofeed=self).
- Replies:
(tno:N) (ofeed:<url>).
- Clients: increment
tnolocally for new threads, copy tags on reply.
- Subjects optional, not required.
…
↳
In-reply-to
»
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
⤋ Read More
@lyse@lyse.isobeef.org True, at least old versions of KDE had icons:
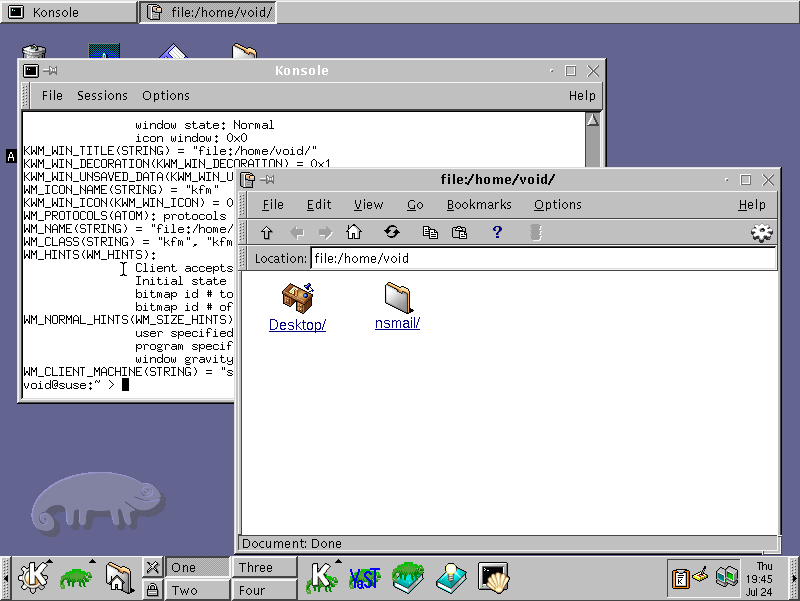
GNOME, on the other hand, didn’t, at least to my old screenshots from 2007:
I switched to Linux in 2007 and no window manager I used since then had icons, apparently. Crazy. An icon-less existence for 18 years. (But yeah, everything is keyboard-driven here as well and there are no buttons here, either.)
Anyway, my draft is making progress:
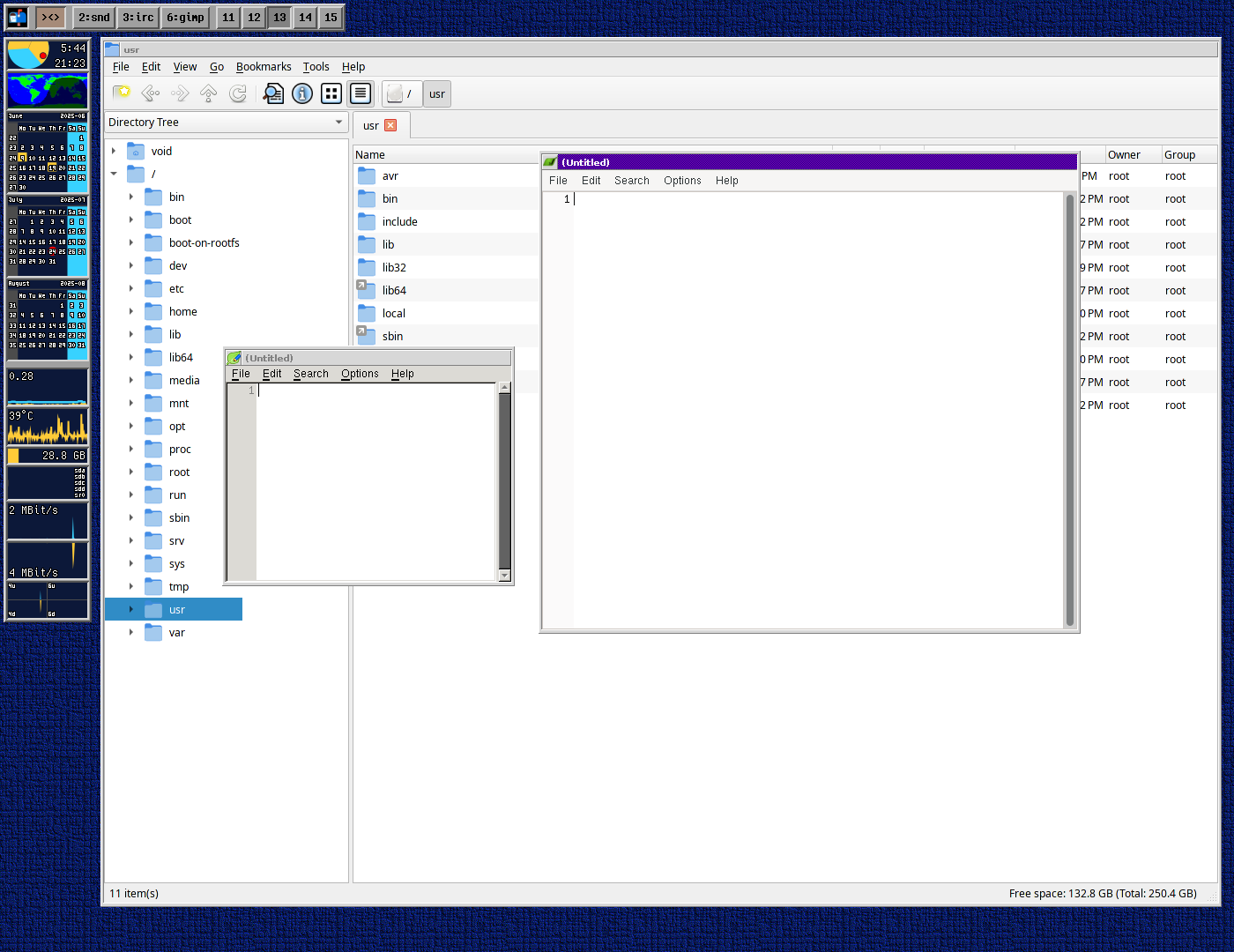
I do like this look. 😊
I was drafting support for showing “application icons” in my window manager, i.e. the Firefox icon in the titlebar:
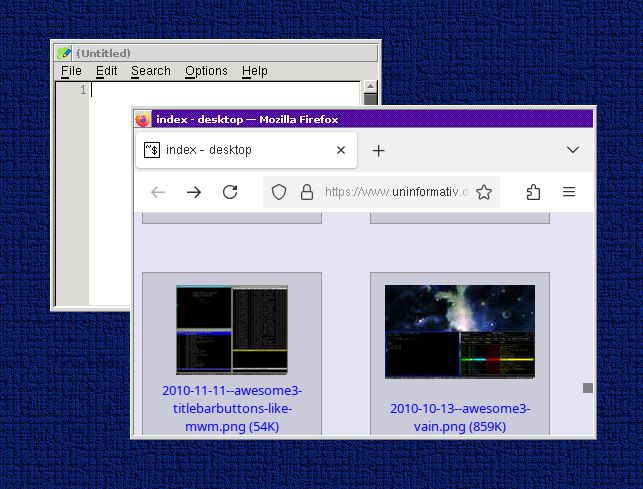
Then I realized: Wait a minute, lots of applications don’t set an icon? And lots of other window managers don’t show these icons, either? Openbox, pekwm, Xfce, fvwm, no icons.
Looks like macOS doesn’t show them, either?!
Has this grown out of fashion? Is this purely a Windows / OS/2 thing?
How to create issues and pull requests in record time on GitHub
Learn how to spin up a GitHub Issue, hand it to Copilot, and get a draft pull request in the same workflow you already know.
The post How to create issues and pull requests in record time on GitHub appeared first on The GitHub Blog. ⌘ Read more
Drafting
 ⌘ Read more
⌘ Read more
Drafting
⌘ Read more
i still want a tux plushie ngl. i’m gonna draft my sister (she can sew) into making me one