↳
In-reply-to
»
I noticed that there are quite a few UI glitches in vim-classic – and quickly found the cause: It comes with outdated Unicode tables.
⤋ Read More
@movq@www.uninformativ.de What kind of Unicode do you use? All the new emojis?
I noticed that there are quite a few UI glitches in vim-classic – and quickly found the cause: It comes with outdated Unicode tables.
I have to admit that I wasn’t aware that there’s a new Unicode release every year:
https://en.wikipedia.org/wiki/Unicode#Versions
Look at this huge number of changes. Every program has to keep track of that, often through libraries but sometimes not (like in Vim’s case).
I use Unicode extensively, but this shit is extremely expensive …
My TUI framework is having the same problem. At the moment, this is all offloaded to wcwidth, but if that library was to become unmaintained, I’d have to track Unicode myself.
Gah!
The DOS days were simpler. CP437, end of story. (Yes, I know that’s a lie.)
↳
In-reply-to
»
@lyse Oh, no, he was the one providing the feedback. 😅
⤋ Read More
@movq@www.uninformativ.de Oh, whoops, hahaha! :-D Yeah, I also noticed Markus’ Unicode work yesterday. Really cool.
↳
In-reply-to
»
@lyse Two emails. 😅 One person asking for the source code, and the author of wcwidth (the library I’m using) contacted me to provide some input. 👌
⤋ Read More
@lyse@lyse.isobeef.org Oh, no, he was the one providing the feedback. 😅
mgk appears to be everywhere. His Unicode box drawing demo has been part of my unicode-test script for a long time: https://movq.de/git/bin-pub/file/unicode-test.html#l23
Unicode 18.0.0 Beta
Article URL: https://www.unicode.org/versions/Unicode18.0.0/
Comments URL: https://news.ycombinator.com/item?id=48290881
Points: 9
# Comments: 1 ⌘ Read more
I recently got an email with this byte sequence:
\xf0\x9f\x8e\x81\xf0\x9f\x95\xaf\xef\xb8\x8f
That’s U+1F381, U+1F56F, U+FE0F. The last one is a “variation selector”:
https://unicodeplus.com/U+FE0F
My toolkit renders this incorrectly – and so do tmux and GNU screen.
Unicode ain’t easy. 🥴
↳
In-reply-to
»
Some work on the menu system to brighten my mood a little bit. No mouse support yet.
⤋ Read More
@bender@twtxt.net I’m already using it for tracktivity (meant for tracking activities and events, like weather, food consumption, stuff like that), which is basically a somewhat-fancy CSV editor:
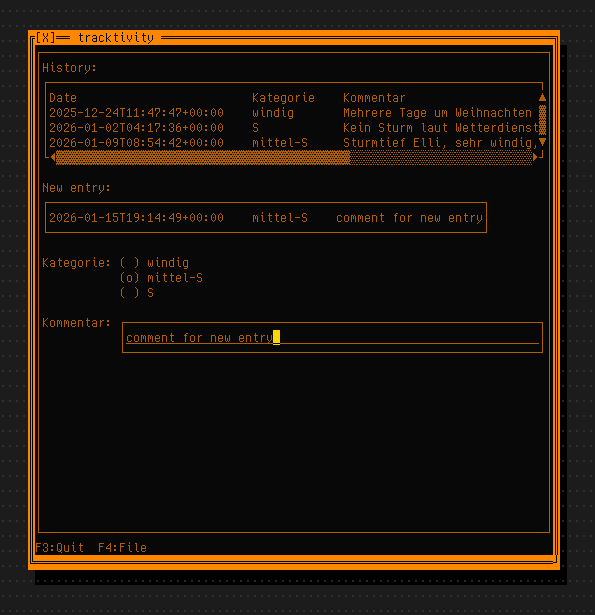
I have a couple of other projects where I could use it, because they are plain curses at the moment. Like, one of them has an “edit box”, but you can’t enter Unicode, because it was too complicated. That would benefit from the framework.
Either way, it’s the most satisfying project in a long time and I’m learning a ton of stuff.
↳
In-reply-to
»
Here am I looking at the different
⤋ Read More
tcell.Key constants and typing different key combinations in the terminal to see the generated tcell.EventKeys in the debug log. Until I pressed Ctrl+Alt+Backspace… :-D Yep, suddenly there went my X…
@movq@www.uninformativ.de Yeah, I know that terminals are super weird and messy. In both the KDE Konsole (identifying itself as TERM=xterm-256color) and xterm (TERM=xterm) it just works flawlessly. My urxvt (TERM=rxvt-unicode-256color) just doesn’t. I also tried messing with TERM in urxvt, but no luck so far.
More widget system progress:
https://movq.de/v/87e2bce376/vid-1767467193.mp4
I like the oldschool shadow effect. 😅 Not sure if I’ll keep it, but it’s neat.
The menu bar is still fake.
Had to spend quite a bit of time optimizing the rendering today. This can get really slow really quickly.
Unicode is Pain.
I might be able to start porting my first program (currently uses urwid) soon. 🤔
Why have these Unicode smilies never caught on, I wonder? 🤪
Well, you girls and guys are making cool things, and I have some progress to show as well. 😅
https://movq.de/v/c0408a80b1/movwin.mp4
Scrolling widgets appears to work now. This is (mostly) Unicode-aware: Note how emojis like “😅” are double-width “characters” and the widget system knows this. It doesn’t try to place a “😅” in a location where there’s only one cell available.
Same goes for that weird “ä” thingie, which is actually “a” followed by U+0308 (a combining diacritic). Python itself thinks of this as two “characters”, but they only occupy one cell on the screen. (Assuming your terminal supports this …)
This library does the heavy Unicode lifting: https://github.com/jquast/wcwidth (Take a look at its implementation to learn how horrible Unicode and human languages are.)
The program itself looks like this, it’s a proper widget hierarchy:
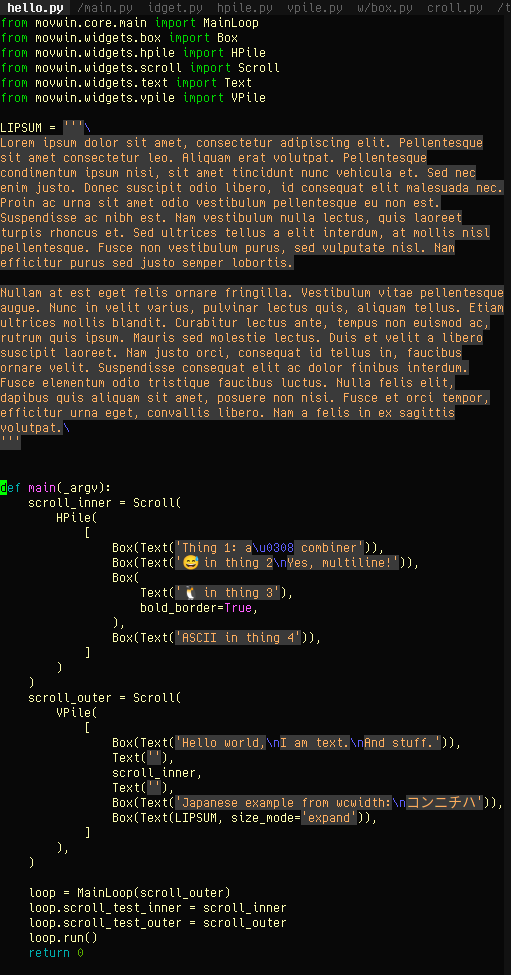
(There is no input handling yet, hence some things are hardwired for the moment.)
↳
In-reply-to
»
@lyse I’m toying with the idea of making a widget/window system on top of Python’s ncurses. I’ve never really been happy with the existing ones (like urwid, textual, pytermgui, …). I mean, they’re not horrible, it’s mostly the performance that’s bugging me – I don’t want to wait an entire second for a terminal program to start up.
⤋ Read More
@movq@www.uninformativ.de I see. Yeah, all the Unicode stuff certainly doesn’t help here, that’s for sure.
Maybe “speedcurses” could be a name. Or just select any Palatinate curse. ;-)
↳
In-reply-to
»
Trying to come up with a name for a new project and every name is already taken. 🤣 The internet is full!
⤋ Read More
@lyse@lyse.isobeef.org I’m toying with the idea of making a widget/window system on top of Python’s ncurses. I’ve never really been happy with the existing ones (like urwid, textual, pytermgui, …). I mean, they’re not horrible, it’s mostly the performance that’s bugging me – I don’t want to wait an entire second for a terminal program to start up.
Not sure if I’ll actually see it through, though. Unicode makes this kind of thing extremely hard. 🫤
Awk to take lines from Plan 9’s /lib/unicode and prepend the actual glyph and a tab: awk ‘{cmd=sprintf(“unicode %s”, $1); cmd | getline c; printf(“%s %s\n”, c, $0)}’
Unicode characters in iskeyword ⌘ Read more
Tag proposal: typesetting
For stories relating to: how text is laid out an
Discussion: should it include e.g. stories about Pango? Unicode (partially relevant to typesetting/typography I suppose)? These are a bit further from “typsetting” but is relevant to typography and encoding? Should it include stories about markup languages?
See searches for e.g. [LaTeX](https://lobste.rs/search … ⌘ Read more
How to display non-printable unicode characters? ⌘ Read more
How to display non-printable unicode characters? ⌘ Read more
↳
In-reply-to
»
@movq I fully agree with you on https://www.uninformativ.de/blog/postings/2025-07-22/0/POSTING-en.html!
⤋ Read More
@lyse@lyse.isobeef.org The underlines are a bit much, yes. It appears to be related to my font (Helvetica) … Maybe they do some Unicode trickery these days, I don’t know. 🫤
fn sub(foo: &String) {
println!("We got this string: [{}]", foo);
}
fn main() {
// "Hello", 0x00, 0x00, "!"
let buf: [u8; 8] = [0x48, 0x65, 0x6C, 0x6C, 0x6F, 0x00, 0x00, 0x21];
// Create a string from the byte array above, interpret as UTF-8, ignore decoding errors.
let lossy_unicode = String::from_utf8_lossy(&buf).to_string();
sub(&lossy_unicode);
}
Create a string from a byte array, but the result isn’t a string, it’s a cow 🐮, so you need another to_string() to convert your “string” into a string.
- https://doc.rust-lang.org/std/string/struct.String.html#method.from_utf8_lossy
- https://doc.rust-lang.org/std/borrow/enum.Cow.html
I still have a lot to learn.
(into_owned() instead of to_string() also works and makes more sense to me, it’s just that the compiler suggested to_string() first, which led to this funny example.)
↳
In-reply-to
»
And to finish the day: Om Live at Pioneer Works 🤘 – https://www.youtube.com/watch?v=IwnDKcoVHmY
⤋ Read More
(Where is there no bass emoji in Unicode? Pah.)
Trinity Desktop Environment R14.1.4 released
The Trinity Desktop Environment, the modern-day continuation of the KDE 3.x series, has released version R14.1.4. This maintenance release brings new vector wallpapers and colour schemes, support for Unicode surrogate characters and planes above zero (for emoji, among other things), tabs in kpdf, transparency and other new visual effects for Dekorator, and much more. TDE R14.1.4 is already available for a variety of Linux distributions, and c … ⌘ Read more
Wild - A high performance, flexible and unicode compliant wildcard matching library
1 points posted by xrfang ⌘ Read more
Understanding surrogate pairs: why some Windows filenames can’t be read
Windows was an early adopter of Unicode, and its file APIs use UTF‑16 internally since Windows 2000-used to be UCS-2 in Windows 95 era, when Unicode standard was only a draft on paper, but that’s another topic. Using UTF-16 means that filenames, text strings, and other data are stored as sequences of 16‑bit units. For Windows, a properly formed surrogate pair is perfectly acceptable. However … ⌘ Read more
(#fmnhewq) @bender@bender Which feed has Unicode newlines in the desc? Hmm 🧐
@bender Which feed has Unicode newlines in the desc? Hmm 🧐 ⌘ Read more
↳
In-reply-to
»
(#ovlagaa) @prologic I'm not a yarnd user, so it doesn't matter a whole lot to me, but FWIW I'm not especially keen on changing how I format my twts to work around yarnd's quirks.
⤋ Read More
@bender@twtxt.net @prologic@twtxt.net I’m not exactly asking yarnd to change. If you are okay with the way it displayed my twts, then by all means, leave it as is. I hope you won’t mind if I continue to write things like 1/4 to mean “first out of four”.
What has text/markdown got to do with this? I don’t think Markdown says anything about replacing 1/4 with ¼, or other similar transformations. It’s not needed, because ¼ is already a unicode character that can simply be directly inserted into the text file.
What’s wrong with my original suggestion of doing the transformation before the text hits the twtxt.txt file? @prologic@twtxt.net, I think it would achieve what you are trying to achieve with this content-type thing: if someone writes 1/4 on a yarnd instance or any other client that wants to do this, it would get transformed, and other clients simply wouldn’t do the transformation. Every client that supports displaying unicode characters, including Jenny, would then display ¼ as ¼.
Alternatively, if you prefer yarnd to pretty-print all twts nicely, even ones from simpler clients, that’s fine too and you don’t need to change anything. My 1/4 -> ¼ thing is nothing more than a minor irritation which probably isn’t worth overthinking.
Unicode doesn’t distinguish between a dollar sign with one and a dollar sign with two strokes, which makes me sad.
Account Problems
 ⌘ Read more
⌘ Read more
Account Problems
⌘ Read more
[Emacs] 替數學符號設定專用字型 ⌘ Read more
Weird Unicode Math Symbols
 ⌘ Read more
⌘ Read more
Weird Unicode Math Symbols
⌘ Read more
someday i will descend upon the unicode consortium and add sub/superscript version of the whole latin alphabet
@lyse@lyse.isobeef.org What the heck? no emoji? do you even Unicode!
↳
In-reply-to
»
Ugh why does Emojipedia sell my data. This is so silly.
⤋ Read More
@prologic@twtxt.net Yeah like normally I’m just a little annoyed and just say “whatever” and shrug it off, but come on I am searching for emojis here. Do you really need to harvest my user data for what is essentially a fuzzy search in the Unicode table?
↳
In-reply-to
»
How fair ye î̸͚n̸͔͋ ̴̰̃t̸̲͝ḧ̸͙́e̴̱͛ ̸̈́ͅd̷̜̕e̵̬̚p̷̨̽t̴͍͆h̶͙̓ṡ̶̩o̵̪̎f̴̧̉ ̵̳̄̄Z̸̩̗̉͊̎a̸͎̹͚̓̌͋l̸͎̰̤̚g̸̛̖̬͇̾ö̵̲͖?̸̫̦̉̇ͅ ̷̡͚̑̓͊
⤋ Read More
@prologic@twtxt.net lol. just testing some Unicode.
PEP 672: Unicode-related Security Considerations for Python
This document explains possible ways to misuse Unicode to write Python
programs that appear to do something else than they actually do. ⌘ Read more
On the blog: Where Have All the Emoji Gone? https://john.colagioia.net/blog/2021/09/29/emoji.html #programming #techtips #unicode #blog
https://metacpan.org/release/WOLFSAGE/perl-5.35.4/changes#Unicode-14.0-is-supported Perl 5.35.4 版之後所對應的 Unicode 版本已經推進到 14.0.0 了。
@prologic@twtxt.net should we enable all unicode glyphs for tags? https://txt.sour.is/conv/55yrura
I wrote a ‘banner’-like program for Plan 9 (and p9p) that uses the Unicode box drawing characters: http://txtpunk.com/banner/index.html
https://www.materialui.co/unicode-characters design unicode web
huh, txtnish seems to have problems with linebreaks & unicode;.
riding an experimental font renderer through unicode’s outer planes, I found curvy, pointy, zigzaggy, cloudy shapes, glyphs that span lines and punch through pages, diacritics that reach back in time, the entire 2045 uplifted octopus emoji set,
go-edlib - String comparison and edit distance library compatible Unicode ⌘ https://github.com/hbollon/go-edlib
Accented and other unicode characters in groff/troff ⌘
PEP 623: Remove wstr from Unicode ⌘ http://www.python.org/dev/peps/pep-0623
PEP 624: Remove Py_UNICODE encoder APIs ⌘ http://www.python.org/dev/peps/pep-0624
Teletext graphics characters among those added to Unicode – Teletext Art http://teletextart.co.uk/teletext-graphics-characters-among-those-added-to-unicode